| |
Overview of Proteus
This section
is for those who are interested in learning more about Proteus without having to cope with too many technical intricacies. Even if you happen to be technically inclined, it will be best to read this section first, as this section provides a quick understanding of several key concepts of the Proteus approach.
Introduction
Proteus (PROcesses and Transactions Editable by USers) is a model that describes creation of clinical guidelines with Knowledge Components (KCs).
Each KC represents a clinically identifiable activity and is available to the clinician as executable knowledge. Experts at disparate locations may manage the individual knowledge components, while the clinicians benefit from the state-of-the-art knowledge. Additionally, the KCs offer a template for capturing data pertaining to the clinical activity that they represent, to provide a basis for the EMR. Since the KCs represent discretely identifiable clinical activities they also allow attaching related elements from non-clinical processes. Each such non-clinical process can be assigned a separate layer, with components within it communicating with a logically related KC in the clinical guideline. This allows conceiving of an integrated healthcare information system with logically related parts and unlimited extensibility.
Proteus is an ambitious approach touching many aspects of healthcare. Prototype software tools have been developed as proof of concept.
Incidentally, Proteus in Greek mythology is the powerful sea god who possessed the knowledge about everything and had the ability to change shape at will. Surely the one to emulate for medical knowledge representation too.
Background and significance
Motivation for guideline-based clinical decision systems
Medical Informatics researchers have devoted significant efforts in creating electronic versions of guidelines. The motivation underlying the development of models for guideline-based care has come from several factors, some of which are as follows:
- Limited success of guidelines in text form
- Gaining of ground by Evidence Based Medicine
- Realization that information and knowledge required for decision-making have to be available at the point-of-care and at the time of decision-making for maximum benefit
- Increasing pressure on providers to reduce the cost of care without compromising quality
- Standardization of care and reduction in variations in its implementation
- Realization that guidelines can help improved allocation of resources.
Besides the drivers listed above a well designed executable guidelines can also:
- Provide effective decision-support to span the entire course of a medical condition as a series of decisions alternating with events or actions, in contrast to the systems that offer isolated one time decision-making
- Allow tracing the audit trail for peer review and performance evaluation, for both medical and legal reasons, since decision dependencies become more apparent than in a conventional non-guideline application.
- Provide continuity of management of conditions, particularly in multi-physician, multi-location settings
Factors that hinder acceptance of existing systems
Despite several guideline-based systems having been proposed, none have found any acceptance. An extensive search of literature shows no reports of use by the clinicians or rigorous evaluations of guideline-based systems in clinical settings. The main reasons for non-acceptance seem to be the following:
- Lack of customizability for different providers. To be useful in the clinical setting the guidelines need more than medical knowledge; they also need to be pragmatic in the location of the use. The knowledge of medical capabilities, population characteristics, disease patterns and socio-economic factors for the location is also essential.
- Complexity. For knowledge-based systems the underlying knowledge representation has to be reasonably well understood by the end-users to allow its management. However, most proposed models are too complex for general users. To create a new guideline or edit an existing one with such systems is difficult. Some of the models have even proposed a language of their own, with no tools having been developed to effectively link the model or the language with the user-interface.
- Lack of tolerance to ad hoc data or ability to use it. Most proposed guideline-based systems are not tolerant of ad hoc data (when data that has not been provided for crops up or expected data comes in at unexpected times). Example: While doing an elective cesarean section the surgeon unexpectedly encounters adhesions and performs adhesiolysis too. If the original guideline does not provide for adhesiolysis and if there is no way of including it at the runtime the system is rendered unusable. It is impossible to achieve the orderliness in clinical arena that the other guideline systems demand. With any unexpected event the physician is compelled to discard the automated guideline approach and switch over to the conventional means of managing the patient, undermining the entire exercise of unified computer-based patient care and data recording.
- No linkage with patient record system. The proposed systems do not provide for linking the guidelines with the medical record systems. Lack of two-way linkage between the guidelines and the patient record forces repetitive data entry and the need to enter the entire data each time the guideline is restarted to assist in deciding the next step.
- No provision for incomplete or unavailable medical knowledge. In the clinical setting the clinician often has to take decisions despite the lack of complete medical knowledge or data. Since medical knowledge is rarely refined to such high granularity for each and every task, the need for human interpolation or extrapolation is obvious. Rigid knowledge based guidelines expect the entire rationale for each step to be available to model it into an implementable action.
- Changes in medical knowledge. Medical knowledge is an inherent and key part of the guidelines; therefore with even a minor change in any of the underlying concepts, the guideline has to be modified to reflect the current state of knowledge. Guidelines can thus become outdated rapidly. Even if the systems were to provide for making the changes, it would be an arduous task to keep pace with exponentially expanding knowledge if keeping the guidelines in sync with changing concepts was solely the providers' responsibility.
- No linkage with non-medical tasks and processes of providers. Essential non-medical processes like managerial and administrative activities are examples. There is no provision for linking medical processes with these parallel processes in most guideline-based systems. It is ironic that despite a major motivation for creation of guidelines and guidelines coming from healthcare managers, no existing guideline-based system provides adequate mechanism to deal with their needs.
- Lack of an intuitive representation of the knowledge and data. The systems have internal representation for guidelines but how the users are going to see them or interact with them is not specified, or the representation of the guidelines is not intuitive for the users.
- Requirements imposed for uniform representation of medical knowledge. There is an assumption by some approaches that development of guideline-based systems can only progress if uniform interpretation of medical knowledge is ensured. However, such a goal is far from achievable. Medical knowledge has always been interpreted in diverse ways in clinical settings. A guideline-based system should only aim to provide expressiveness for all possible interpretations rather than be concerned with how the knowledge is interpreted.
- Efforts to develop dedicated inferencing technology. The guideline system developers have not only been defining the architecture of their systems, but have also been trying to create inferencing technology for use in their models as an innate part of the system. This has increased the complexity of the models while limiting each approach to a specific technology. More recently, some approaches have made provisions for more than one inferencing technologies. However, these technologies are incorporated within the models; the inferencing technologies that are not a part of the model are excluded from use. For instance, a system may not be able to use technologies like Artificial Neural Networks or image segmentation based inferencing if these are not explicitly included in the underlying model.
- Dependence on machine inferencing for all tasks. Implicit in several guideline-based approaches is that all decisions will be made only by machine. Since guidelines span different kinds of inference making situations, trying to adapt a single inferencing technology or even several of them to meet these needs is likely to face problems. The most versatile inferencing tool known, the human intelligence, is thus ignored. An ideal framework would allow use of any inferencing technology, including human intelligence, depending on the task.
- Lack of psychological ownership of the system. “The technically best system may be woefully inadequate if its implementation is resisted by people who have low psychological ownership in that system”. A higher sense of ownership may be achieved for a system in healthcare setting if there is an active involvement of healthcare professionals in its creation.
The design of the Proteus model aims at avoiding these pitfalls.
The Proteus Model
Proteus – (PROcesses and Transactions Editable by Users), is a model for creating executable clinical decision-support guidelines. The name and the abbreviation signify flexibility and maneuverability of guidelines in the hands of physicians. The guidelines in Proteus approach are built from small bits of knowledge in the form of software entities, called knowledge components (KCs). The KCs are discrete, editable, reusable and executable, distributed knowledge entities that represent clinical activity. The design of the KC has been achieved by applying principles of distributed component software architecture to knowledge forms. The KCs can be created and maintained by experts while healthcare professionals access them from remote locations. Because of the independent nature of each of the KCs, a change in one KC does not affect others. Additionally, the KCs capture the data entered, thereby also serving as components of the Electronic Medical Record (EMR). This kind of medical record is far richer than conventional records since it also records the decisions made and the basis of the decisions, in addition to the raw data.
Since the guidelines represent clinical processes, representations of other processes in healthcare that are dependent on the clinical processes may be linked to the guidelines. Examples of such processes are billing, supplies, administration, nursing, etc. Each such process can be represented as a layer parallel to the core clinical process and its components have representation similar to KCs in the clinical process with which they are linked. Proteus thus provides a mechanism to construct complete healthcare information systems in which each part is logically related to another. Moreover, since any number of layers can be added, the system based on Proteus has unlimited extensibility.
Another essential feature of Proteus-based guidelines is that they are not tied to a particular technology for inference making. Indeed, each KC can have its own inference tool based on the technology most suitable for its purpose. Diverse technologies can be used to achieve inferencing. Human experts may also be declared as inference tools providing an approach to bringing collaborative decision-making to the point of care. The inference tools may be changed to one using a different technology, even while a guideline is being executed.
For the clinician, these features translate into accessing executable knowledge that is updated automatically, always reflecting the state of the art. The clinician can also get the support of collaborative decision-making from a team, which may be geographically distributed. The clinicians at any stage may override the inferences offered by the automated tools or the remote experts, by declaring themselves as the ‘inference tool’ for the task at hand. Additionally, Proteus provides means to visually represent the executable KCs and guidelines constructed with them. A notation system that is human-readable as well as machine-readable, allows the users to interact with the knowledge and modify it. The KCs and the notation system are designed for organizing and displaying information in a way that reduces complexity and facilitates decision making by the clinician.
These features give an incentive to the clinician for entering the data at the point of care as entering the data leads to decision support that is based upon the state-of-the-art with the best inference approach, and helps in avoiding medical errors.
Run the animated tutorial to get a quick feel for the Proteus environment.
Proteus – A brief Overview of the Essential Features
The following features of the Proteus technology are covered below:
The Knowledge Component |

The accompanying figure shows a knowledge component (KC). KCs are entities that represent clinical activities such as clinical action, event or clinical process. Because each KC is an independent, distributable software component entity, it may change or evolve without affecting the function of other KCs that use it and is unaffected by changes outside it. Within an application that understands its clinical semantics, the KC is an executable entity. The KC contains data that pertains to the underlying action or event that the KC represents. Thus, KC also serves as a template for data recording and as a data storage component, a part of an EMR system.
The data is aggregately represented by the abstraction, which represents the value for the KC. For instance, a KC – ‘Symptoms of Diabetes’ would have abstraction value true if its data-elements ‘Polydipsia’, ‘Polyuria’ and ‘Unexplained weight loss’ all had values true. Via abstraction, the KC presents a single value to entities external to it, regardless of how many items it contains internally.
The KCs also have inference tools that are accessed via an interface. There are two types of Inference tools one each to create, abstraction inference or action inference. The abstraction inference creates or updates the abstraction for the KC whenever any data change takes place within it. (E.g., abstraction of the KC ‘Symptoms of diabetes’, in the example may change from unknown to true once values have been filled in its data-elements). The action inference controls the launching of KCs representing other clinical activities within a KC that represents a clinical process. |
Knowledge components can be nested |

The KCs that represent clinical processes allow nesting of other KCs within them to indefinite levels.
This allows representation of complex clinical processes. The abstraction (described above) gives a single value for a KC, even if the KC contains numerous other KCs within it, allowing reduction in complexity. When data changes within a KC, its inference tool changes its abstraction. This triggers a change of its container’s abstraction, and so on, until this cascade of abstraction changes reaches the outermost container, the guideline. Thus the implications of any change are apparent immediately. It is the inference tool of a process KC that decides which nested KC to be launched. The ability to nest, along with the ability to link (described below), allows KCs to be used to create clinical guidelines, even complex ones. |
Inference tool is separate from the KC |
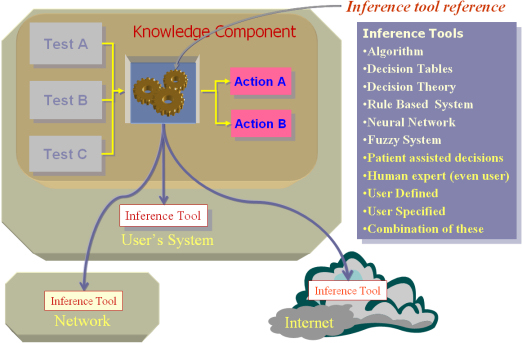
Since the inference tool is present within a KC only as a reference and accessed via an interface, the actual tool may be located anywhere: on the user’s system or on any other system accessible via the local network or the Internet. Additionally, the actual technology behind the reference could be one from many technologies, regarded to be most suitable for the task represented by the KC (the inset shows some of the technologies that may be used). Moreover, this makes them pluggable devices – one inference tool may be swapped for another. Switching of inference tools does not disrupt the functioning of other parts of the KC. The inference tool only has to be faithful to the specified interface for such tools. |
Knowledge components can be linked |
Within clinical processes, sequencing or co-occurrence of activities can be represented. The activity transition is represented by the activity links. The activity links may be sequential, inferential or synchronous. This allows proper workflow representation. Linking and nesting (described above) are necessary for representing clinical guidelines. |
Knowledge is separate from the Application |
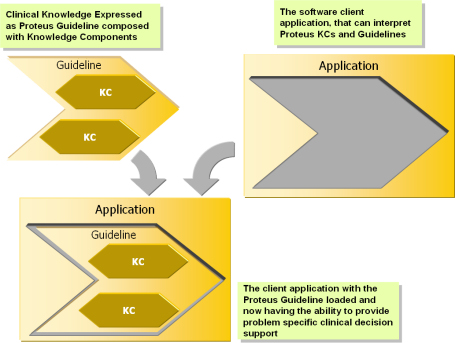
Separation of knowledge from the application allows the same application to be used for many different kinds of situations. It also allows knowledge to be soft-coded as opposed to hard-coded. |
Proteus notation – An example guideline |
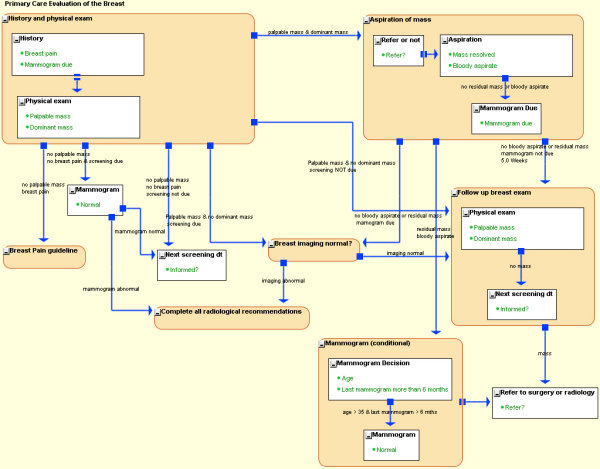
To allow clinicians to interact with the KCs, the KCs need to be represented in a form that unambiguously communicates the clinical semantics. For this purpose, Proteus has a notation system (Proteus Graphical Language – PGL), which is human-readable as well as machine-interpretable.
The language is easy to learn and most clinicians can master it in minutes.
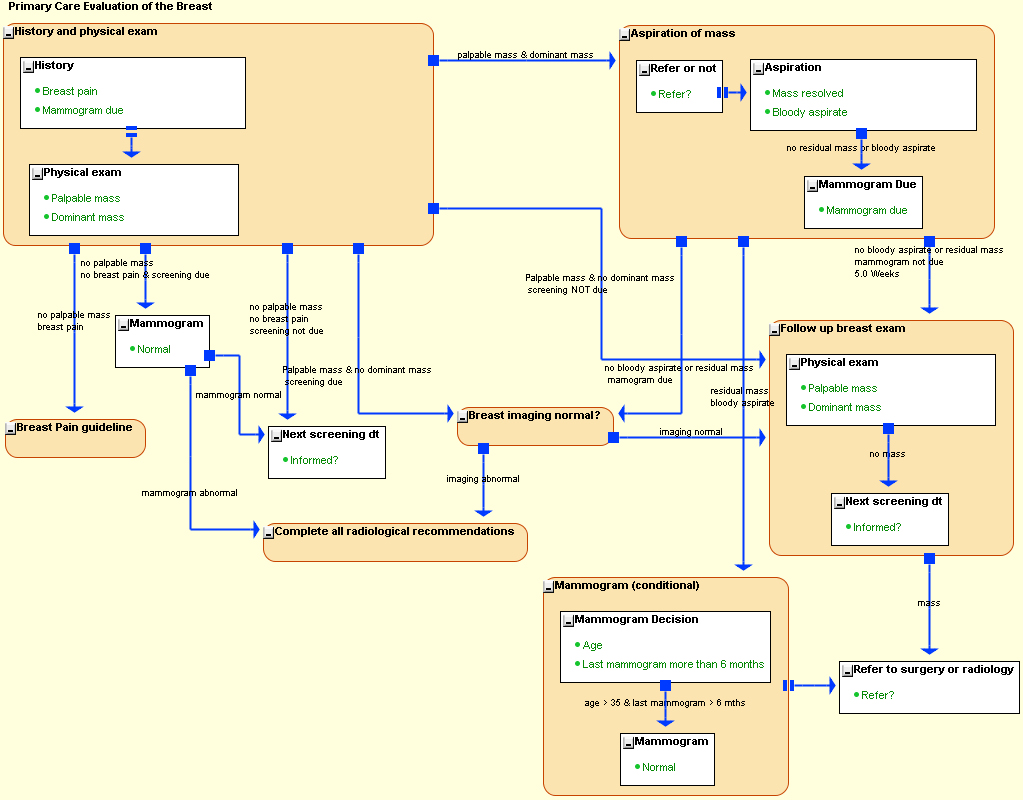
The illustration shows a guideline in PGL, for investigation of a breast lump. Click the figure to see a larger version of the guideline.
The rectangles represent clinical event or action (atomic KC) while the rounded rectangles represent the clinical processes (process KC). The processes may also have other activities contained within them. The arrows between KCs depict activity transitions, specifying which activities can follow. The shape of the source end of the arrows indicates whether the subsequent activity is to be launched by an inferencing mechanism (a filled square) or is simply sequential (a pair of parallel bars). |
Execution |
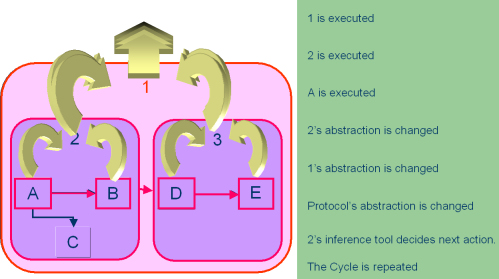
This figure shows the sequence of execution of KCs in a guideline. Every time an atomic KC (shown as squares) is encountered in the course of execution, it acquires data from the clinical world, most often by user entering the data in a dialog box created by the KC. Once the data is submitted, it triggers an abstraction cascade. The abstraction cascade consists of change of the abstraction of the atomic KC itself and then successively of its containers, until the abstraction of the outermost container, the guideline is also changed. Only after the cascade has finished the next action is triggered. If this action is an inferential one, the action inference tool of the container KC decides if it has to be launched or not. |
Layers – extensibility for other healthcare processes |
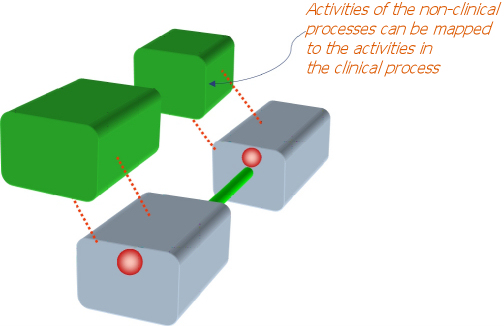
Since a KC represents something distinctly identifiable in terms of clinical activity, KCs are convenient anchor points for components of other (non-clinical) processes in healthcare. For example, though the clinician may be concerned with the information that would help make decisions about cytology and mammography, the healthcare manager would be interested in providing the resources and logistical support to facilitate and optimize the process, and to monitor the activity.
Similarly, other healthcare personnel may be linked with the core (clinical) process. Each such process can be defined as a layer. The core layer (clinical process) keeps other layers, such as those for the administrator, researcher, account section or others informed about events within it. The layers feature allows the Proteus approach to be the basis of a comprehensive and integrated healthcare information system. New layers, even ad hoc ones can be created, allowing unlimited extensibility. 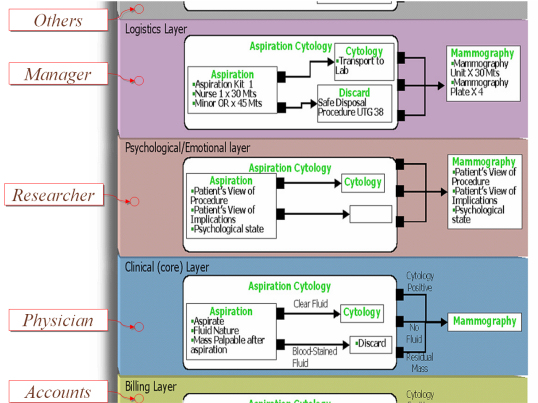 |
Object oriented design of Proteus |
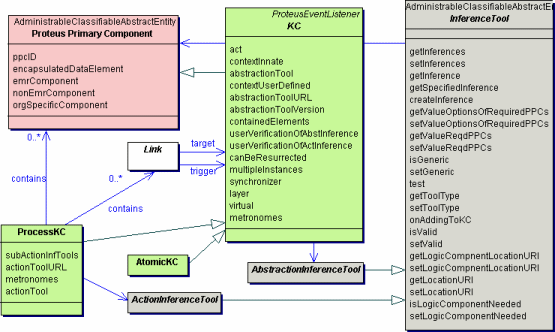
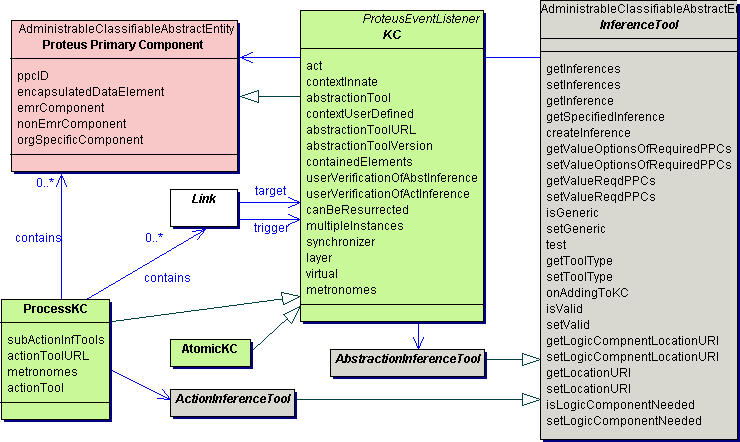
Underlying the Proteus approach is the information model represented in the standard Unified Modeling Language (UML). This is an abbreviated UML class diagram with some important classes of the Proteus model. Click on the diagram to see a bigger view. The turquoise classes are from a model from a data element repository (ISO/IEC 11179). To explore the Proteus UML model further look in the technical section of this website.
|
Overview of a Proteus-based system
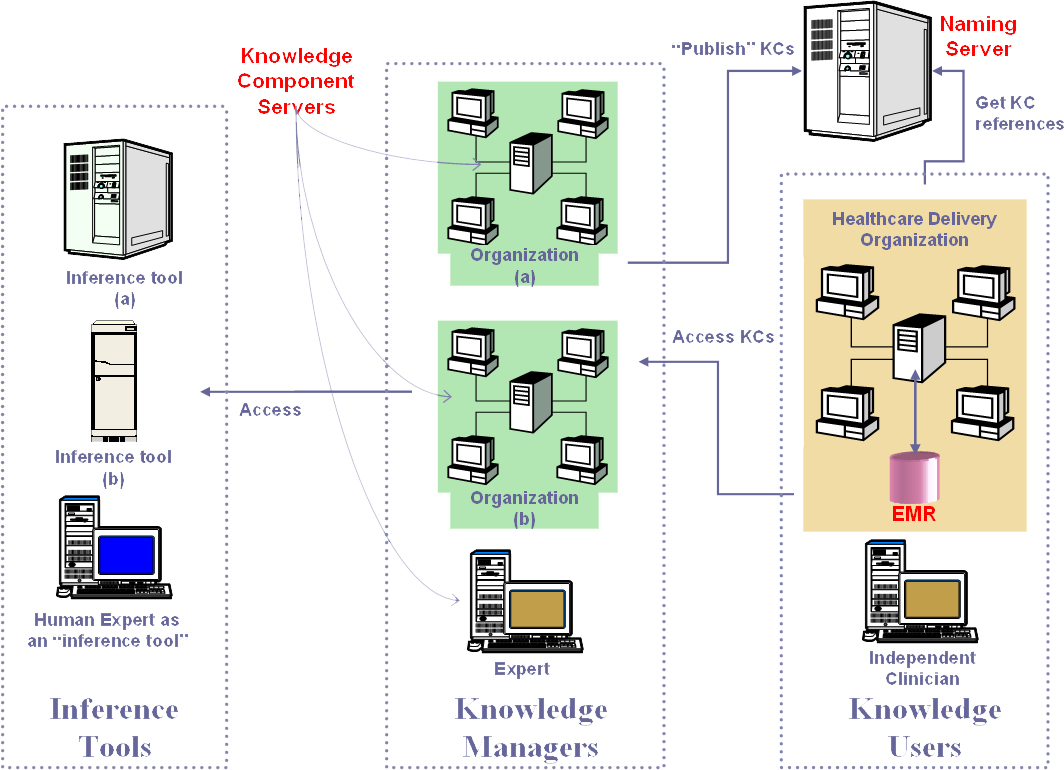
This section takes a perspective view of a full-fledged system based on the Proteus approach. Please refer to the diagram below for this part. Click the diagram to see a bigger version.
A core facility in a Proteus-based clinical decision-support system is the knowledge component server hosting the KCs including the guidelines (which are top level KCs). The knowledge managers (professional organizations and individual experts) are authorized agents/agencies that create and maintain the KCs at their own locations, and intermittently publish them by binding them with a name on the naming/directory server, making the KCs accessible to authorized users. The KCs may access inferencing tools located at other secure sites as remote services. Some human experts would also be designated as ‘inference tools’ for certain KCs for which such inferencing is appropriate. The naming server maintains a list of all the KCs, classified and organized to facilitate negotiating to the desired KC, associating each name with a KC reference. The clients access this naming service to get references for KCs to allow instantiating them. The actual KCs including the guidelines are hosted in KC servers in different locations authorized for knowledge management.
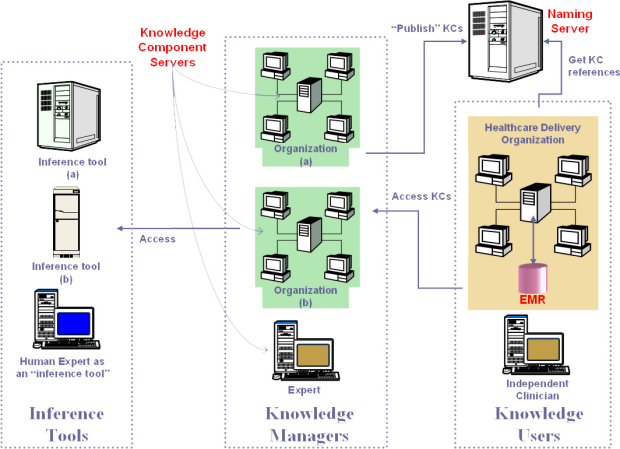
The users (knowledge users), with the client software, obtain the reference to the KCs from the naming server and then use the references to access the KCs from the KC server. The client software (like Protean) provides an environment for the users to visualize, execute and edit the guidelines and KCs. It allows the users to see the patient data, thus serving as the front end of the EMR. The EMR that is created, based on the templates that KCs provide, is stored at the healthcare provider facility. The users may store the knowledge components they have modified, or those they create de novo, at their own location. The knowledge managers also use the client as a tool to create and maintain KCs. |
Knowledge Component server
In the planned implementation, the KC server is an application server based on EJB specification. This provides the users access to KCs, while allowing the knowledge managers to maintain them. The application servers provide features for deploying and maintaining components based on the Java 2 Enterprise Edition (J2EE) industry standard. Specifically, it provides a way to deploy software components called Enterprise Java Beans (EJB). The KCs are available to the client application in the form of EJB entity beans. The server also provides the mechanisms to locate the KCs, security, linking to database, linking with web-based applications, transaction management, ability to use legacy tools via CORBA, among other features. The underlying database is an RDBMS that is accessible via JDBC, which would store each KC in a record.
Alternative architectures are also in consideration. For example, the KCs may be accessed in a peer-to-peer network, where the physicians would be able to share the KCs created by them without a central server. In another possible approach, the naming service and also the KC servers could be conceived of as Web Services (WS). WS is a standard for accessing components over HTTP using XML based remote method invocation. |
The Client Tool – Protean
The Proteus framework is primarily oriented towards assisting the clinician at the point of care. The tools that the clinicians use therefore are an important part of the framework. Protean, an end user tool is an example of client application, primarily for clinicians’ use. Protean allows accessing of KCs and Proteus guidelines, their visualization, maintenance, and execution. Protean is expected to evolve into the front end of the Proteus based EMR and Order Entry System. Though Protean is primarily a front-end tool for a server-based system, it may also serve as a standalone tool. A tutorial to introduce users to Protean is available. The tutorial also provides instructions for downloading and installing the current version of Protean. |
|

{kind=link}